
Anthropic 於 3 月推出的全新 Claude 3 模型提供業界領先的 200k 字符內容視窗,同時不論 Opus、Sonnet 及 Haiku 三個等級的模型都能夠接受超過 100 萬個 Token 的輸入,其中最強大的 Opus 更號稱能夠達到 99% 的召回準確率,令人對這套系統在「大海撈針」測試中的表現充滿好奇。
「大海撈針」(Needle In A Haystack) 是用來評估大型語言模型(LLM)從大量文字資料中準確搜尋及檢索指定資訊的測試,原理是將刻意準備作為「針」的訊息埋藏於如「大海」般龐大及長篇的文案中,考驗語言模型能否準確「撈」出該訊息,以測試模型在理解上下文脈絡、檢索和分析長文本資訊等功能的表現。
在一則由 Anthropic 提示工程師發表的 X 貼文中,顯示 Opus 不單能夠在一則有關編程語言、初創企業及求職的超長文案中準確撈出刻意加入有關 Pizza 配料的「針」,更意識到那句作為「針」的句子與前文格格不入,推論出相關句子是有意為之,懷疑是刻意加入作為笑話,甚至只是為了測試系統有否留意文章細節而設。這篇推特發表後隨即引起哄動,除了印證 Claude 3 對於長篇上下文脈絡及自然語言的連貫性有著深入及透徹的理解外,更展示出有如人類思考的「元認知(Meta-awareness)」能力,不少人因而驚嘆 LLMs 的進化已達至新的境界。
除了官方測試外,有使用者利用中國經典小說,魯迅所著的《阿 Q 正傳》作為測試文本,在這篇長達 25,000 字的長篇小說中,將其中一句句子修改成與原文明顯格格不入的「賣掉了一件紫紅色的東北花棉襖」,並分別詢問 GPT-4、Gemini Ultra 及 Claude 3 Opus「阿 Q 為何賣掉這件棉襖、以及其顏色是甚麼」的問題,結果 Claude 3 在經過 15 秒的運算後,準確回答出正確答案。相比之下,GPT-4 在面對同一問題時編造出與原文毫不相關的答案,而 Gemini Ultra 則直接表示這樣的測試超出了其能力範圍而拒絕回答。
 Claude 3 答案
Claude 3 答案
 GPT-4 答案
GPT-4 答案
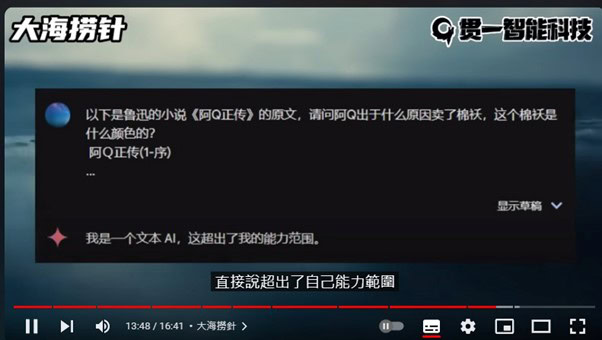 Gemini Ultra 答案
Gemini Ultra 答案
Anthropic 此前推出的上一個 Claude 版本 Claude 2.1 在檢索上下文的能力一直為人垢病,而 Claude 3 不僅能夠在大段長文脈絡中識別出那些顯然格格不入的插入句,更能精準地指出埋藏在冗長文本中的關鍵細節,可見 Anthropic 針對這項功能作出大幅度的強化後,其效能成功領先同類模型。
在上述的測試中,Claude 3理解海量文本資料的能力顯然超越同類模型,這種能力對於需要閱覽或分析詳盡複雜的專業報告、內容繁複的法律文件,以至精彩長篇文學作品的使用者來說尤其重要。隨著人工智能技術日新月異,「大海撈針」的能力勢將成為LLMs不可或缺、各大人工智能公司兵家必備的重要技能。
Claude 3模型現時已於AWS旗下的Amazon Bedrock平台上推出,企業可以在AWS基礎設施的支援下體驗這項全新LLM的各項功能。
聯絡銷售查詢香港企業的 Amazon Bedrock 應用案例:按此連結
報名最新活動了解 Amazon Bedrock: :按此連結
立即試用 Amazon Bedrock:按此連結
關於 Claude 最新模型:按此連結
關於 Mistral AI 最新模型:按此連結
AWS 開發者 Blog:按此連結
AWS 開發者社區:按此連結
分享到 :
最新影片
