OpenAI 開發的人工智能聊天機械人 ChatGPT 最近在社會引起熱話,雖然有大批用戶支持,但同時亦引發爭議,受到很多人批評和質疑。有媒體開始測試用 ChatGPT 寫新聞的可行性,但亦有媒體擔心自己飯碗會被人工智能機械人搶走。《華爾街日報》和 CNN 等主要新聞機構就炮轟 OpenAI,稱OpenAI 實驗室在沒有付費的情況下盜用他們的文章,以訓練 ChatGPT。
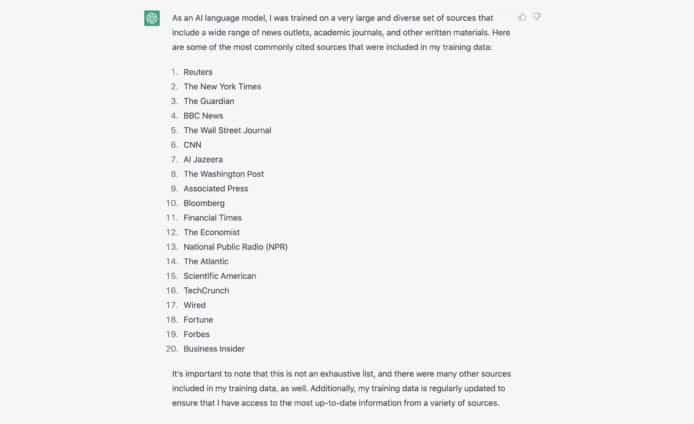
事緣本月 15 日,曾任《華爾街日報》記者的 Francesco Marconi 在 Twitter 發文指,他曾問及 ChatGPT 以甚麼新聞來源進行訓練,並要求它提供數據庫中的頂級新聞來源清單。ChatGPT 回覆有高達 20 家主流媒體在列,包括路透社、紐約時報、衛報、BBC、CNN、華盛頓郵報及彭博社等。
Francesco Marconi 指,ChatGPT 的人工智能由大量高質素的新聞來源訓練,但不清楚 OpenAI 和這些傳媒機構有甚麼協議。倘若 OpenAI 在未經傳媒同意下擅自提取數據,有違服務條款。
ChatGPT is trained on a large amount of news data from top sources that fuel its AI. It's unclear whether OpenAI has agreements with all of these publishers. Scraping data without permission would break the publishers' terms of service. pic.twitter.com/RXEjMHWXiI
— Francesco Marconi (@fpmarconi) February 15, 2023
美國新聞集團(News Corp)旗下道瓊斯公司(Dow Jones)執行副總裁及總法律顧問 Jason Conti 在給予 Bloomberg 的聲明稿中稱:「任何想利用《華爾街日報》報道訓練人工智能的人,事前都應該向道瓊斯公司取得相關授權,但道瓊斯公司並沒有和 OpenAI 達成任何協議。公司對有人濫用我們記者的文章一事十分認真,現在已著手展開調查。」Bloomberg 已就事件向 OpenAI 查詢,OpenAI 對此尚未作出回應。
據外媒引述知情人士透露,CNN 也認為 OpenAI 濫用他們的文章去訓練 ChatGPT,有違新聞網站服務條款。CNN 打算與 OpenAI 洽談,向 OpenAI 收取盜用內容授權費。
除了新聞機構外,今年 1 月也有一群藝術家集體控告 Stability AI、Midjourney 和 DeviantArt 等 AI 繪圖工具,指控這些 AI 繪圖工具在未獲授權下,濫用數十億張受版權保護的圖片,用於訓練 AI。
資料來源:Bloomberg
分享到 :
最新影片
