
Google 推出全新文本生成圖像 AI 工具「Imagen」,並公開一系列由 Imagen 生成的圖片。
Google 旗下深度學習與人工智慧科研專案團隊 Google Brain,近日發布了一系列由新的文本生成圖像 AI 工具「Imagen」制出的成果。Imagen 透過解析用家所輸入的文字而生成寫實的圖像,更能突破人類的想像力。

在雪地裡戴著空手道腰帶的火龍果。(A dragon fruit wearing karate belt in the snow.)

機械人在水浸的莫奈美術展覽中使用槳板。
(An art gallery displaying Monet paintings. The art gallery is flooded. Robots are going around the art gallery using paddle boards.)
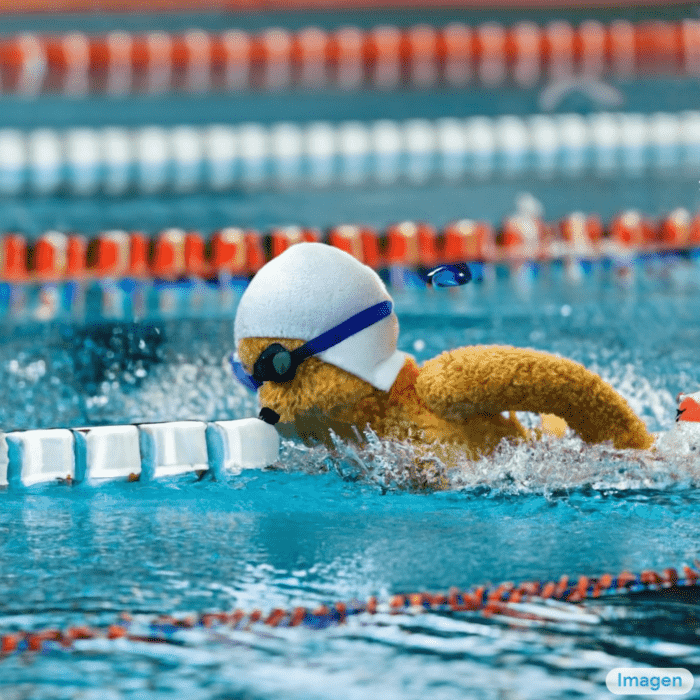
泰迪熊在奧運 400 米蝶泳項目中游泳。(Teddy bears swimming at the Olympics 400m Butterfly event.)
圖片來源: Google
Google 透過 DrawBench 圖像模型基準測試來評估 Imagen 的文字生成圖像能力,較 VQ-GAN、LDM 及 DALL-E 2 等同類型工具比,Imagen 生成的圖像逼真度更高,語言理解能力亦更好,與輸入的文字較為符合,偏好率更高達 50%。與 DALL-E 2 相比,Imagen 能準確地為圖像配色,而 DALL-E 2 則容易混淆多個顏色指令的文字。
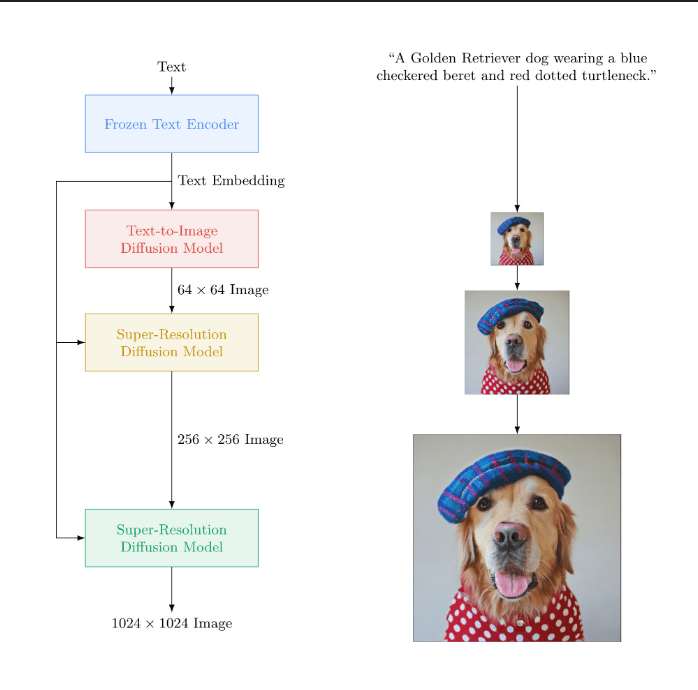 圖片來源: Google
圖片來源: Google
Google 表示,由於 Imagen 在生成圖像過程的評估工作尚有不足,導致在生成圖像時出現一些社會和文化偏見,亦傾向西方對性別的刻板印象,例如膚色及對職業的描繪,更出現色情圖像、種族主義攻擊言論等的不當內容。因此在有關問題修復前,將不會對外開放 Imagen 的程式碼,更不會對外展示。
資料來源:Deccan Herald
—
unwire.hk Mewe 專頁 : https://mewe.com/p/unwirehk
分享到 :
最新影片
